Elephant provides the Indicator API as a way to generate statistics from entities. The main goal of the API is to facilitate the generation among modules, on separated DBs.
Indicators are usually stored using a separated convenience API. Examples of using indicators are the Ranking and Matching APIs. Both take indicators values and store them where needed, independently of the source of the stored data.
Main goals
- Inheritance from AbstractIndicator, concentrating efforts on providing data.
- Discovering indicator classes via annotations.
- Isolated from the storage mechanism, both when generating or reading.
- Ability to find indicator values with a sound syntax, based on the storage APIs.
- Statistics.
Indicator composition
Since indicators are stored using separated APIs, the indicator may vary in its composition. For example, the Ranking API relates to sets of single entities, while the Matching API does with two entities. Provided that storage depends on others and Indicator API needs read access, the API imposes some requirements.
- Entities should be stored in the standard Elephant mechanism.
- Table names and entity names must correspond.
The reading mechanism
Since indicators solely generate and provide data, seems that being able to read this data on a separate process is far off its possibilities.
The reading mechanism comes in help and is able to provide indicator values for statistic purposes. To achieve this goal, indicators find storage classes and provide an specific syntax for reading its values at single, multiple or formulated basis.
Reading syntax
The form taken by readIndicator parameter is:
JPAEntityClass:IndicatorClass:entityPath[:relatedPath]:indicator
|
JPAEntityClass |
These classes are usually named after their functionality. You can see an example in Ranking
, where the class |
|
IndicatorClass |
Class that owns the JPA Dao and has the ability to read values. |
|
entityPath |
Refers to the entity to be read. Notice that |
|
relatedPath |
Same as for entityPath but for the related entity. This field has meaning only when reading a matching indicator. |
|
indicator |
Refers to which indicator will be returned. For indicator the |
Wildcards
|
* |
Represents one or more characters. |
|
? |
Represents a single character. |
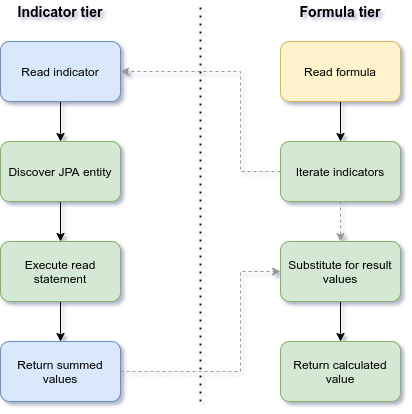
Discovering indicators
To understand how reading syntax helps locating values, this image shows the process of getting values.
Optimizations
Indicators are created from within modules and using JPA contexts. The results are stored at module convenience in order to be accessible for database queries. The Ranking API and the Matching API assist saving results in specialized tables. This would be the standard, and preferred, method.
Before diving into possible process optimizations, let's see some numbers.
Quantifying results
A ranking set of indicators will create (indicators + final_ranking) * entities tuples. For instance, if you have 500 entities and need 10 indicators to calculate the ranking value, this will create (10 + 1) * 500, 5,500 tuples. Not so bad.
A matching set of indicators will create (indicators + final_matching) * entities * related_entities tuples. Things have slightly changed since there is another factor: the related or entities to match with. The matched entities are usually contacts. Let's do the same example as above, saying that we have 1,000 contacts to match with. Applying the factor to the previous result give us the amount of 5,500,000 tuples. Quite impressive, isn't?
Three optimization approaches
Spare zeros is a first approach to optimize the results. The API does not save zero or near to zero values. The impact of this optimization highly depends on the related selection of the second approach, but is at least significant for non relevant indicators.
Fine selection approach affects both entities and related entities. It's difficult to implement since implies some kind of guessing which pairs are prone to match. The impact of this optimization is high because supposedly eliminates zeros and, more important, reduces the number of database reads.
Bulk data might be the more effective approach. Makes an initial selection and does de insertions as a pre-process. When doing so, the indicator does not have to load entities separately, knows the result from the read data.